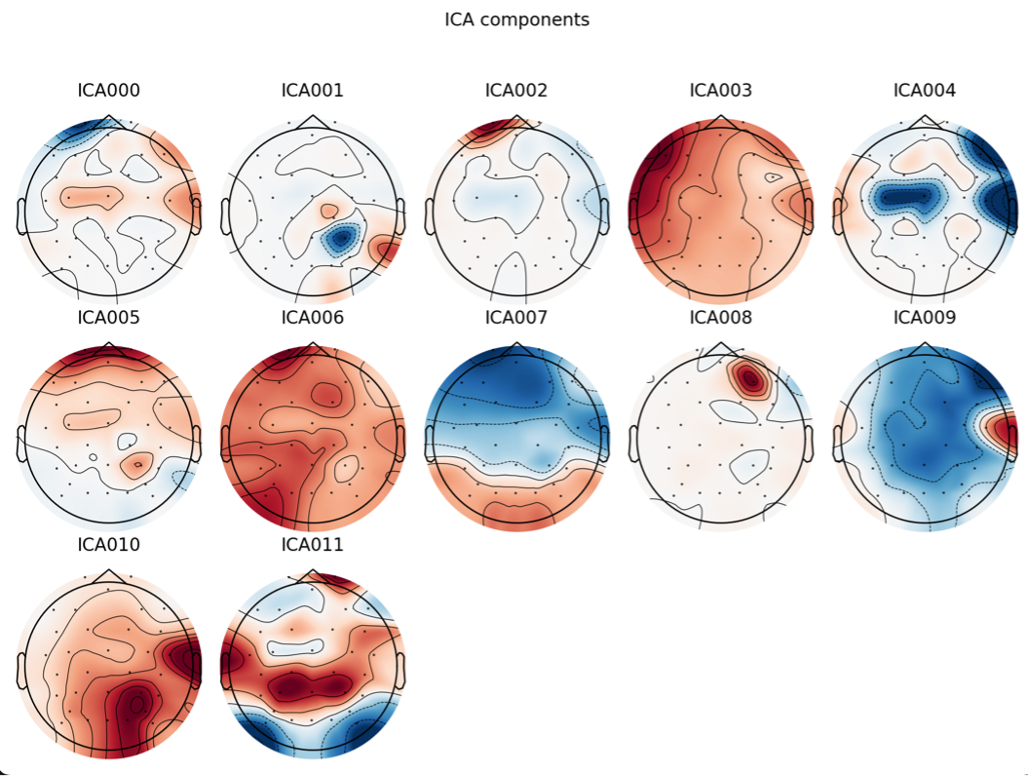
P300 ERP is evoked when a person perceives a target stimuli, and it associates with the decision-making process that something important had occurred.
For classifying P300 event-related potential, usually need prior knowledge about the EEG signal during the target and non-target stimuli. However, different classifiers need different amounts of data to achieve a usable classification ability. In this final project, I explored 4 different classifier...
Read more
03-21-2023
brain-computer-interface
machine-learning
CNN